Geoparsing
Geoparsing es un proceso de análisis automático del lenguaje para detectar menciones de entidades geográficas y codificarlas en sus coordenadas. Dicho, grosso modo, se analiza el lenguaje y se obtienen mapas. Con miras al desarrollo del primer geoparser para español de México se han desarrollado simultáneamente varias líneas de investigación con metas parciales pero gracias a las cuales se ha podido integrar finalmente el software. Las secciones siguientes ofrecen un panorama muy somero de las líneas de investigación que desarrollamos.
Reconocimiento de Entidades Nombradas
El Reconocimiento de entidades nombradas (NER por sus siglas en inglés) es una tarea de extracción de información que busca localizar y clasificar entidades mencionadas en un texto en categorías predefinidas: personas, organizaciones, lugares, expresiones de tiempo, entre otras. Así, un módulo de NER debe procesar bloques de texto libre, como el siguiente:
Jim, originario de Seúl, compró 300 acciones de Acmé Corp. en 2006.
Y producir un bloque de texto anotado con las entidades detectadas:
<PERSON>Jim</PERSON>, originario de <LOC>Seúl</LOC>, compró 300 acciones de <ORG>Acmé Corp.</ORG> en <TIME>2006</TIME>.
En el ejemplo anterior, han sido detectados y clasificados el nombre de una persona, un nombre de ciudad, un nombre de compañía de (dos tokens o unidades léxicas) y una expresión temporal. Actualmente, los sistemas de reconocimiento de entidades para el inglés tienen un rendimiento cercano al humano pero cabe mencionar que para el español hay cierto rezago debido en parte a que hay menos corpora disponibles y los analizadores léxicos suelen ser menos sofisticados.
Geographic Entity Recognition
En esta investigación abordamos especificamente la tarea conocida como Geographic Entity Recognition (GER), también llamado reconocimiento de expresiones locativas (LER) o reconocimiento de expresiones espaciales, la cual busca detectar lugares y su posición o su relación geográfica con otros objetos o lugares georreferenciables. En GER existen dos complejidades adicionales al NER clásico: la primera complejidad es que existe una cantidad enorme de topónimos, lo que resulta en un alto grado de ambigüedad; la segunda complejidad es que el objetivo final es atribuir referencias geográficas a las entidades, lo que resulta en una dificultad adicional pues se resuelve a través de un módulo adicional que consulta recursos externos.
El siguiente es un ejemplo de un texto que contiene varias entidades georeferenciables, las cuales han sido detectadas mediante las técnicas que desarrollamos en esta investigación:
Con su gira Huevos Revueltos , Hombres G y Enanitos Verdes ,
agrupaciones que han dejado huella en el rock en español ,
llegarán a <LOC> Puebla </LOC> el viernes 16 de marzo.
El escenario será el <LOC> Centro Expositor </LOC>
de la zona de Los <LOC> Fuertes de Loreto y Guadalupe </LOC>
en esta ciudad , donde las agrupaciones deleitarán al
público con las canciones y ritmos que las hicieron legendarias,
de acuerdo con un comunicado .
Al concierto se esperan seguidores provenientes de <LOC>
Tlaxcala </LOC> , <LOC> Estado de México </LOC> ,
<LOC> Veracruz </LOC> y <LOC> Oaxaca </LOC> ,
quienes gozarán de esta fiesta del rock en español .
La detección de entidades geográficas recae en un modelo de reconocimiento generado con técnicas de aprendizaje supervisado.
Geoparsing en servicio web
Para usar el Geoparser como un servicio web utilice la URL:
http://geoparsing.geoint.mx/ws/
mediante petición HTTP POST Request enviando, en el cuerpo de la petición, un parámetro "text" con el texto a procesar.
Por ejemplo:
{
"text": "Un grupo de presidentes municipales del país inicia hoy en Mérida
la creación de una red de ciudades con buenas prácticas policiales con el
fin de mantener o mejorar la seguridad pública en sus comunidades.
Por iniciativa del alcalde Renán Barrera Concha y el liderazgo de la
asociación civil Causa en Común, que dirige la activista ciudadana
María Elena Morera Mitre, los alcaldes mexicanos invitados realizarán
la mesa de diálogo “Trabajo Sociedad más Gobierno,
la Construcción de Ciudades Seguras”.
Será una reunión privada en un salón del Centro Cultural Olimpo.
}
generará como salida:
{
"labeled": "Un grupo de presidentes municipales del país inicia hoy en <LOC>Mérida</LOC> la creación de una red de ciudades con buenas prácticas policiales con el fin de mantener o mejorar la seguridad pública en sus comunidades .\nPor iniciativa del alcalde Renán Barrera Concha y el liderazgo de la asociación civil Causa en Común , que dirige la activista ciudadana María Elena Morera Mitre , los alcaldes mexicanos invitados realizarán la mesa de diálogo “ Trabajo Sociedad más Gobierno , la Construcción de Ciudades Seguras ”. Será una reunión privada en un salón del <LOC>Centro Cultural Olimpo</LOC>.\n",
"entities": [
{
"index": 1,
"entity": "Mérida",
"context": "Un grupo de presidentes municipales del país inicia hoy en Mérida la creación de una red de ciudades con buenas prácticas",
"nonimatim": [
{
"boundingbox": [
"20.8733088",
"21.0867259",
"-89.7261963",
"-89.5301684"
],
"class": "place",
"display_name": "Mérida, Yucatán, México",
"icon": "/nominatim/images/mapicons/poi_place_city.p.20.png",
"importance": 0.57816344305869,
"lat": "20.9670759",
"licence": "Data
...
Corpus de Entidades Georreferenciadas de México
El Corpus de Entidades Georreferenciadas de México, CEGEOMEX propuesto por (Molina-Villegas et al., 2021) fue creado para desarrollar algoritmos de detección de entidades geográficas. CEGEOMEX fue anotado manualmente gracias al apoyo de la Red Temática en Tecnologías del Lenguaje y al Consorcio en Inteligencia Artificial CONACyT. CEGEOMEX cuenta actualmente con un total de 5,870 entidades nombradas georeferenciables etiquetadas a partir de un corpus con 361,946 palabras distribuidas en 1,233 documentos de noticias de los principales medios digitales de México. Los criterios de la anotación de CEGEOMEX así como su uso en un modelo de reconocimiento de entidades están descritos detalladamente en Aldana-Bobadilla et al., 2020.
Reconocimiento de Entidades Georreferenciadas basado en Word Embeddings
Para el reconocimiento de Entidades Geográficas desarrollamos nuestro propio módulo de Geographic Entity Tagging basado en un clasificador de red neuronal entrenado con vectores densos obtenidos a partir del Corpus de Entidades Georreferenciadas de México. La red neuronal de clasificación evalúa los embeddings (vectores densos) del texto a etiquetar para determinar si un token es Geographic Entity o no lo es.
Los embeddings se obtuvieron a partir de tokens procesados utilizando el módulo word2vec (Mikolov et al., 2013). Además de los word embeddings se ha utilizado un Context Encoder (ConEc). El entrenamiento del ConEc es idéntico al del word2vec, con la diferencia en el cálculo del word embedding después de que el entrenamiento se completó. En el caso de word2vec, el embedding es la fila de la matriz \(W_0\) mientras que en el caso de ConEc se crea la representación de la palabra multiplicando \(W_0\) con el vector de contexto promedio \(x_W\) de la palabra. Se hace la distinción entre el vector de contexto local y global de una palabra. El vector global se calcula como el promedio de todos los vectores binarios de contexto \(x_{w_i}\) correspondientes a las \(M_w\) ocurrencias de \(w\) en el corpus de entrenamiento, de acuerdo a la ecuación \ref{eq413}.
\begin{equation} x_{w_{global}} = \frac{1}{M_w} \sum_{i=1}^{M_w} x_{w_i} \label{eq413} \end{equation} Mientras que el vector de contexto local se calcula como se muestra en la ecuación \ref{eq414}. \begin{equation} x_{w_{local}} = \frac{1}{m_w} \sum_{i=1}^{m_w}x_{w_i} \label{eq414} \end{equation} donde \(m_w\) corresponde a las ocurrencias de \(w\) en un solo documento. Así, el embedding de una palabra se calcula como se muestra en la ecuación \ref{eq415}. \begin{equation} y_w = (\alpha \cdot x_{w_global} + (1 - \alpha) \cdot x_{w_local})^T W_0 \label{eq415} \end{equation} con \(\alpha \in [0,1]\).La elección de \(\alpha\) determina qué tanto énfasis se le da al contexto local de la palabra, lo que ayuda a distinguir entre múltiples significados de una misma palabra. Como una palabra fuera de vocabulario no tiene un vector de contexto global (ya que no pertenece al corpus de entrenamiento), su embedding se calcula tomando en cuenta únicamente el contexto local, es decir, tomando \(\alpha = 0\).
Finalmente, para usar el modelo clasificador de entidades geográficas, el texto es codificado vectorialmente, evaluado por el clasificador y reconstruido. Todo el proceso de Geographic Named Entity Recognition es detallado en (Aldana-Bobadilla et al., 2020).
Conclusiones y perspectivas de trabajo futuro
Hemos presentado las ideas principales subyacentes a los métodos avanzados de Geoparsing en discurso libre para español de México, principalmente enfocándonos en el reconocimiento de entidades con word embeddings. Los resultados de la propuesta implementada son de calidad comparable al de las bibliotecas más importantes en el estado del arte de Procesamiento de Lenguaje Natural y superior en el caso de noticias en español de México.
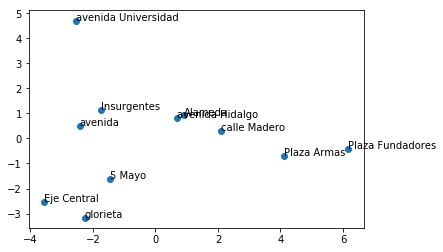
Un aspecto muy interesante del modelo de reconocimiento de entidades geográficas basado en word embeddings es que parece relacionar de manera coherente las entidades con sus correspondientes vecinos de nivel geográfico. Como puede apreciarse en la Figura 1 y Figura 2, los embeddings de "Mérida" y "calle Madero" proyectados en el espacio generado por sus dos primeros componentes principales tienen vecinos asociados a ciudades y a vialidades respectivamente. Este efecto lo hemos estudiado únicamente a nivel meramente exploratorio pero parece prometedor puesto que de confirmarse dicha hipótesis, se podría explotar para determinar niveles geográficos además de reconocer entidades quedando así varias líneas de investigación.

Grupo de trabajo e instituciones participantes
Centro de Investigación en Ciencias de Información Geoespacial
- Dr. Alejandro Molina Villegas. Responsable Técnico: Procesamiento de Lenguaje Natural, Minería de datos;
- Dr. Oscar Sanchez Siordia. Coordinador del centro e Investigador titular: Reconocimiento de Patrones, Geomática;
- Ing. Sergio Gongora Euan. Programador de sistemas.
Centro de Investigación y Estudios Avanzados del Instituto Politécnico Nacional - Tamaulipas
- Dr. Edwyn Javier Aldana Bobadilla. Investigador. Aprendizaje de Máquina, Algoritmos Híbridos;
- Shanel Daniela Reyes Palacios. Tesista de posgrado.
Centro de Investigación en Matemáticas - Monterrey
- Dr. Víctor Hugo Muñiz Sánchez. Investigador. Aprendizaje estadístico supervisado y no supervisado, análisis exploratorio de datos y técnicas de reducción de dimensión;
- Jean Michel Arreola Trapala. Tesista de posgrado;
- Filomeno Alberto Alcántara Alonso. Tesista de posgrado.
Referencias
- [Molina-Villegas et al., 2021] Molina-Villegas, A., Muñiz-Sanchez, V., Arreola-Trapala, J., & Alcántara, F. (2021) Geographic Named Entity Recognition and Disambiguation in Mexican News using Word Embeddings. Expert Systems with Applications. (114855).
- [Aldana-Bobadilla et al., 2020] Aldana-Bobadilla, E., Molina-Villegas, A., Lopez-Arevalo, I., Reyes-Palacios, S., Muñiz-Sanchez, V., & Arreola-Trapala, J. (2020). Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text. Remote Sensing, 12(18), 3041.
- [Molina-Villegas et al., 2019] Molina-Villegas, A., Siordia, O., Aldana-Bobadilla, E., Aguilar, C. and Acosta, O. Extracción automática de referencias geoespaciales en discurso libre usando técnicas de procesamiento de lenguaje natural y teoría de la accesibilidad. Procesamiento del Lenguaje Natural. (SEPLN), 2019.
- [Sang y De Meulder, 2003] Sang, E. F. y De Meulder, F. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050. 2003.
- [Arreola, 2019] Arreola Trapala, J. Reconocimiento de Entidades Nombradas Georeferenciables con Word Embeddings. Tesis de posgrado Centro de Investigación en Matemáticas Unidad Monterrey, Agosto 2019.
- [Mikolov et al., 2013] Mikolov, T., Chen, K., Corrado, G. y Dean, J. Efficient estimation of word representations in vector space. CoRR, vol. abs/1301.3781, perspectivas 2013.
- [Alcántara, 2019] Alcántara Alonso, F. Métodos de desambigüación para Geoparsing en Textos en Español. Tesis de posgrado Centro de Investigación en Matemáticas Unidad Monterrey, Agosto 2019.